Source code can be downloaded from Github
Before starting my own digital marketing and analytics company back in 2011, I had a career in software development behind me. At the time, I had a lot of experience with search algorithms, data collection, storage, and processing. I had been using open source repositories for years and often used these projects as starting points for my software projects. One of my favorite things to do is write tools for my own company. I don’t have to write all of our SEO tools, there are some mature platforms that we use such as Screaming Frog and SEMRush that meet our needs just fine. But, to stay ahead of competition, I often build proprietary systems that allow us to produce something unique that offers high value to our clientele.
My favorite repo is Apache.org. This is a well-run organization which currently has over 300 top level projects. I am constantly working through the project demos to learn how a project may be useful to our SEO team and how it may be integrated into our tech stack. One of the projects that I’ve become interested in is OpenNLP. The Apache OpenNLP library is a machine learning based toolkit for the processing of natural language text. There are many reasons why an SEO company needs to work with NLP, and we have several tools developed inhouse that work with natural language. What really interested me in the OpenNLP project was how easy it was to train models for different purposes.
The OpenNLP toolkit has a command line interface and an API for application development. The command line interface is an excellent tool for familiarizing yourself with all of the toolkit’s features.
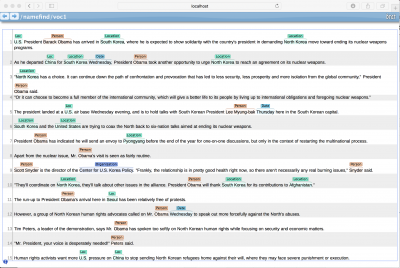
There are several components of the toolkit that perform different NLP functions such as Language Detection, Part Of Speech tagger, and Document Categorizer. For the purpose of this article I’m going to demonstrate the Name Finder function. The technical term for finding things like names, addresses and such is Named-Entity Recognition, abbreviated as NER. An entity in this case can be a person’s name, a location, time, phone number, address, a VIN for a vehicle, or really anything. The cool thing is, OpenNLP models can be trained to extract and label any types of entity.
The input box at this top of this page allows you to enter a URL, and the name entities on that page will be returned. This demo is using the demo model that comes with the toolkit, so it may not be perfect, but it’s close enough to get the idea. A little additional training would spruce up the results pretty good. The code samples are in java and intentionally kept simple for clarity.
I assume that you are able to create a java application and add the OpenNLP dependencies.
For maven:







