
Google strives to provide accurate results for all search queries, currently delivering roughly 8 billion searches daily, with over 90% of the current global market of search engines. In order to obtain a full set of the resources available as a set of results, they have created a collection of information that spans the entire internet. This is referred to as the ‘Google index,’ and it is something that Google has continually updated and refined since their founding.
Upon the publication of a new page on the internet, Google will detect and ‘crawl’ this page. This means that it will render all visual and text elements and coordinate it into a set of code that is more digestible for their purposes. Your website is a part of the index and each public page should be crawled, but the amount of information Google will collect on you will vary by site and by page. There are various methods of monitoring your status in the index, as well as means of improving what is collected so that it is as accurate as possible.
(And shout-out to Craig Whitney and Michela Leopizzi for the help researching and editing this post!)
How to Check if My Website is Indexed by Google
There are many ways to monitor the crawl status of your page – or collection of pages, or even website from the perspective of a search engine.
Some of these will require various levels of access and site ownership – but some of the methods listed below are accessible to anyone on the web.
The URL Inspection Tool
The URL Inspection Tool is found inside of Google Search Console. Search Console is a must-have for any site owner and digital marketing professional working with a website.
URL Inspection allows you to input a URL and returns virtually everything you need to know about a page’s crawl and indexation status in Google.
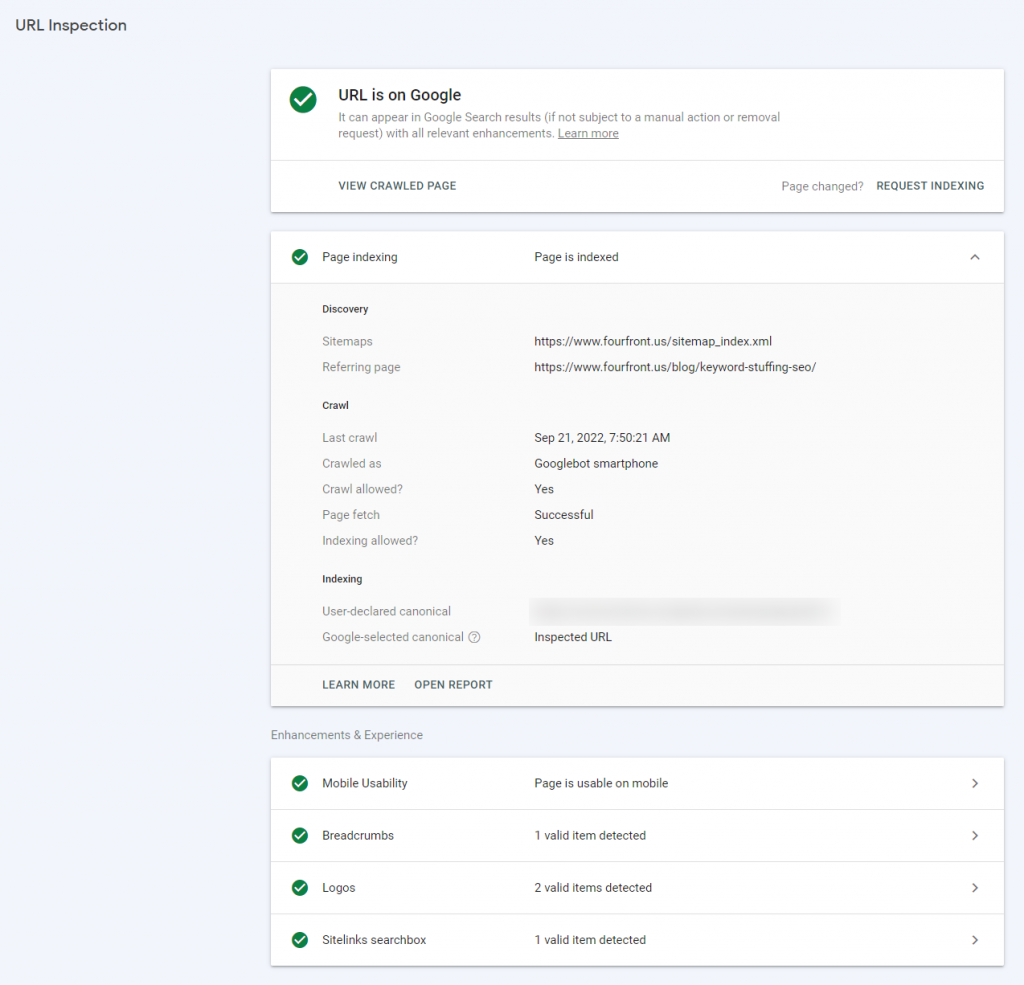
As you can see in the screenshot, URL Inspection can provide you with just some of the following details:
- Is the page on Google?
- Was the URL discovered in an XML sitemap?
- When was the page last crawled?
- Does the page have mobile issues?
- Is the page eligible for additional SERP enhancements (Breadcrumbs, Logo, Sitelinks searchbox, etc.)?
Pro tip: use the URL Inspection API! If you want to check the crawl status of your entire website, you can combine tools like Screaming Frog and URL Inspection to check the crawl status and indexation status of every page on your website. Keep in mind that there are API limits, though. Google’s Search Console URL Inspection API limits users to 2,000 queries per day – which may present a problem for larger websites.
If you really want to see how Google is seeing your website, you’ll want to use the “View Crawled Page” function within the URL Inspection details.
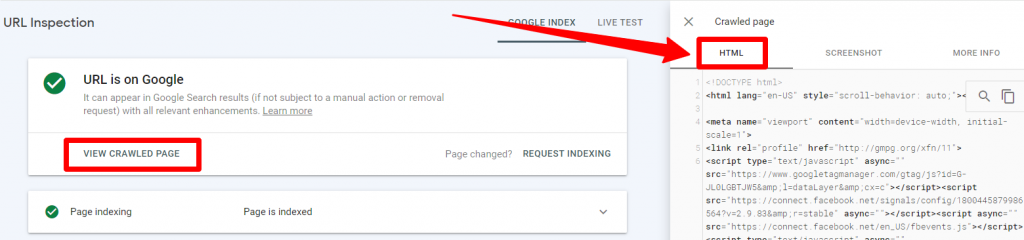
This allows you to see the crawled HTML of the page. In other words: this allows you to see the exact HTML that Google was able to see and crawl in order to “read” your webpage.
This is incredibly helpful for ensuring that all of the main elements and content on the site is “readable” by Google – and that Google is seeing your website and webpage exactly how you intended.
View the Source Code
If you aren’t able to use the URL Inspection tool, you can still get some of the information I just mentioned.
Viewing the source code doesn’t tell us exactly what Google is seeing. But as we all have come to learn: Google is a pretty smart search engine. It’s usually a safe bet that if you can find it in the source code (ensure it’s not just a comment and commented out!), Google’s crawler (Googlebot) will be able to crawl and read your page in the same way.
You’ll need some experience in reading HTML to know what you’re looking for. But if you do have experience in HTML (even at a basic level), you should be able to search the source code and ensure all of the main elements are active, readable parts of the page.
You can use view source by adding “view-source:” in front of your URL. This will open up a new browser tab (if you’re using Chrome) with the HTML of the page.
Chrome Developer Tools
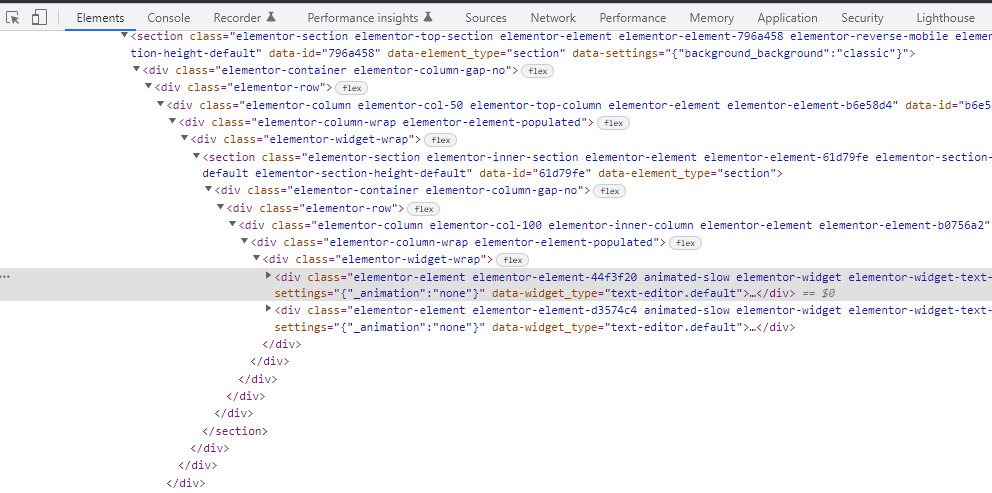
Want to see the source code and interact with it in real time? You can do that using Chrome Developer Tools.
If you’re using Google Chrome as your browser, you’ll simply right-click and click on the “Inspection” item in the menu. This allows you to do many things, including:
- Inspect the page and interact with individual elements
- See active CSS details for respective HTML elements
- Check for errors on the network tab
- Check page status code on the network tab
Search Operators
Another alternative to see how Google is viewing your website is to use various search operators. For those unfamiliar with search operators, a search operator is a specific string used within Google to narrow your results.
The most helpful operators for seeing how Google sees your website are:
- “site:” + “com” – this will help you see how many pages from your website Google has indexed (mydomain is a placeholder here).
- “cache:” + “URL” – this will allow you to view Google’s cache of a specific The cache is effectively a snapshot of the rendered page as Google saw it on the respective crawl date (found in the summary text at the top of the page).
How to Affect the Google Crawl
Now that we know how to check how Google is viewing your website and your webpages – how can you impact the way Google is crawling and interacting with your site? Here are a few common methods:
Meta Tags
Meta tags are directives inserted into the HTML of a webpage that give Google and other webcrawlers specific direction on how to crawl it.
There are two prominent meta tags that I want to mention here: “noindex” and “nofollow.”
Noindex provides search engines with the directive that they can crawl the URL, but the page should not be included in its index. In other words: you can crawl the page, but do not make it eligible for search results. This is commonly used for landings pages that are apart of non-SEO marketing campaigns (social campaigns, Paid Search, etc.).
Nofollow provides search engines with the suggestion* that they should not follow any links. This can be issued at a page-level or an individual link level.
*Note: there is a very specific reason I did not use “directive” and used suggestion instead. Google had historically treated “nofollow” as a directive, but in 2019 started treating “nofollow” as a “hint” instead.
The URL Inspection Tool
Notice a common theme yet? URL Inspection is another valuable tool, particularly when it comes to aiming to influence Google’s crawler.
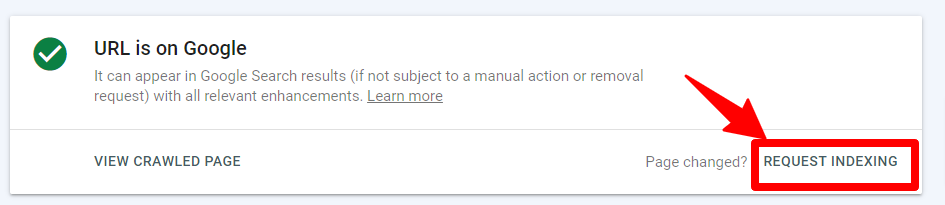
Using URL Inspection, it is possible to submit a URL to Googlebot’s crawling queue. This does not guarantee the page gets crawled immediately, but it does give you some influence.
You can find this feature by clicking “Request Indexing” in the URL Inspection tool.
Common Crawling Issues
Ideally, your website – and its individual pages – will be easy for Google to crawl, render, and index.
Unfortunately, this isn’t always going to be the case. It’s not only important to know how to investigate how Google is going to see your page, it’s important to understand the common crawling issues Google faces for a troublesome page. Here are a few common issues to look for in your diagnostic process.
Loading Errors
Loading errors are a common crawling issue for web crawlers and indexation engines alike. 404 (Page not found) errors – as well as other 4xx and 5xx status codes – bring web crawlers to “dead ends” on your websites. URLs with these status codes are also non-indexable, making them ineligible for search results.
- Potential solution: clean up broken links on your website and ensure all pages are returning 200 (OK) status code.
Dynamically Loaded Content
Dynamically loaded content is often generated via JavaScript. This type of content can be fine for Googlebot, but it can lead to problems if the JavaScript fires after initial page load. This could lead to Googlebot not “reading” the dynamic content when it first loads the page.
- Potential solution: aim to use static content where possible. If you’re unable, use URL Inspection to ensure Google is “reading” your dynamically-loaded content.
- Additional pro-tip: if you’re unfamiliar with JavaScript and its impact on your pages, you can also use a free tool like What Would JavaScript Do to see what elements of your page are generated via JavaScript.
Site Speed and Crawl Budget
Site speed is a commonly known metric and is widely thought of to be a user behavior metric. The faster a page loads, the better the experience, right?
That’s certainly true, but site speed also impacts a webcrawler’s ability crawl (and index) a website. We like to think Google has unlimited capability, but it does work within a “crawl budget” for websites to ensure that it’s not overloading any given website in its attempt to crawl and index a site.
It’s important to note “crawl budget” isn’t a fixed number for a website – a site’s crawl budget is largely dictated by the site’s ability to effectively manage Googlebot without overwhelming the site or server response time.
- Potential solution: optimize site speed as much as possible. Strategies such as caching and CDNs could be potential solutions to improve site speed when delivering large files.
Linked and Large Files
Google doesn’t just crawl webpages – it also crawls any additional resources like PDFs your site may be linking to. While Google does crawl these relatively well, just remember that these files are also contributing factors to your website’s crawl budget (as described above).
- Potential solution: we recommend keeping your important content on HTML pages to ensure Google can (1) efficiently crawl these pages, and (2) ensure smaller load times for Googlebot.
How to Resolve Crawling Issues
If you’re experiencing crawling issues, there are a variety of methods you can use to resolve issues. Here are just some of the more common issues – and how to resolve them.
Correct Poorly Optimized Content
If your content is not well optimized, there is the potential that Google will choose to ignore or not index it properly. This includes issues like:
- Duplicate content (internal and external)
- Hidden content
- Excessive keyword manipulation, including keyword stuffing and inauthentic language
- Link overuse/natural anchor link usage
In short: ensure your content and pages are natural and abide by Google’s best practices for writing content for your target audience.
Resolve Unintended Blocking Meta Tags
It’s always important to check the effected page for any conflicts with the meta tags referenced above, especially the noindex directive. If the noindex directive is found on the page, Google will not index the page and make it eligible for search results.
Optimization
There are multiple ways to encourage Google to find your webpages (and your content!), including several on-page optimizations and off-page optimizations.
Some high-level on-page optimizations include:
- Strong internal linking strategies
- Image optimization (for image recognition)
Some off-site optimizations include:
- External link building
- Local citations
- Social media visibility
The State of Google Crawls
Google is regularly providing updates on its webcrawler, Googlebot. And more importantly, it’s constantly tweaking its ranking algorithm to serve higher-quality results for a user’s search.
It’s important to keep up with these updates to ensure Google is not unintentionally blocked from reading your website or webpages. Need help following these updates? Contact a member of our SEO team for the latest SEO news and strategies to ensure your website stays visible on Google.
Launch your new site with confidence.
Getting ready to launch a new version of your site, but haunted by the horror stories of lost traffic and tanking rankings?
Our FREE SEO Site Transition guide can lead you safely and successfully through the process.
Get it in your inbox now.





2 Comments
thank you for the article. is there a way to know the google crawl budget? or is it a black box?
Hi Mark – sorry for the late response!
It’s a bit of a black box — BUT! The best advice I can give you would be to check your web logs to get a better sense for how often Googlebot is pinging your website. Using these files, you should be able to estimate, on average, how often Google crawls pages on your website (unique daily/monthly URLs crawled).
Cheers!
– Jared
Comments are closed.